本文是CryptDB代码分析的第三篇。在CryptDB中,需要对加密过程进行记录:比如某个表的原始名字和加密以后的名字,表中有多少列,每列用了什么样的加密算法。这些信息被记录在mysql-proxy端的embedded MySQL中。CryptDB使用了元数据管理的模块处理这些信息,相关代码主要位于main/dbobject.hh以及main/schema.cc。
层次化的结构 在介绍元数据相关的类层次之前,我们首先考虑什么样的元信息需要被记录。我们创建一个数据库,需要在元信息里面记录新添加了这个数据库db 。我们进一步在这个数据库里面建立一个表student,使用的语句是CREATE TABLE student (id integer),这样的话,元信息里面就需要记录新加入的表 student ,并且需要知道这个表包含一个整数列id。由于要对数据做加密,这个整数列会被多种不同的洋葱加密,元信息里面也要包含这些内容。由于洋葱有很多的层次,那么每个洋葱处于哪一层也要被记录下来,这样才可以完成正确的加解密流程。
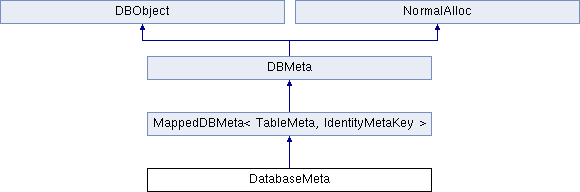
当我们使用语句CREATE DATABASE db 创建一个数据库db的时候,CryptDB会生成一个DatabaseMeta结构来表示这个新的数据库,并把这个信息序列化以后写入到embedded MySQL中。该类的结构如下:
可以看到DatabaseMeta继承了模板类MappedDBMeta,而MappedDBMeta又继承了DBMeta类,下面分别介绍。
1)MappedDBMeta
MappedDBMeta是一个类模板,实例化以后被DatabaseMeta等一系列的类继承,其内部包含了std::map类型的成员,用于保存元数据的层次化关系。举例来说,一个数据库db 下面,会建立很多的表,如**table1,table2,table3…**,这样的话可以通过一个如下的map来保存这种关系:
1 std::map<KeyType, std::unique_ptr<ChildType> > children;
在CryptDB中,下层结构被称为child,上层和下层是包含关系,比如一个DatabaseMeta中就包含多个TableMeta。对于DatabaseMeta来说,map中的KeyType是IdentityMetaKey ,是对表名字如table1 的封装,而ChildType则是TableMeta,代表了一个表的元数据。所有继承了MappedDBMeta的元数据管理相关的类,都是通过map结构用Key-Value的方式来保存这种层次关系的。此外,MappedDBMeta还实现了继承自DBMeta的一些和child操作相关的函数,如:
1 2 3 4 5 6 7 8 9 10 std::vector<DBMeta *> fetchChildren(const std::unique_ptr<Connect> &e_conn); bool applyToChildren(std::function<bool(const DBMeta &)>); AbstractMetaKey const & getKey(const DBMeta &child);
分别用于获取children,对每个child执行一个函数操作,以及通过child来获得child对应的key。
2)DBMeta:
DBMeta类继承了DBOjbect和NormalAlloc,其中提供功能的是DBObject,其作用是给给元数据相关的类记录一个id 。本文介绍的所有元数据相关的类,都从DBObject中得到了id 这个成员。此外,DBMeta类还定义了MappedDBMeta中用于对child做处理的纯虚函数。这样,各种常见的元数据相关的类都可以通过DBMeta的指针来保存,并执行相应的操作对内部保存在Map中的children进行处理。
除此之外,其中还定义了纯虚函数:serialize,各个下层的类实现这个函数,对自身的结构做序列化,并存储在数据库中。
最后,DBMeta中还定义了函数doFetchChildren ,该函数会执行SQL语句,从数据库中读取序列化后的元数据管理类,做反序列化操作,然后以vector的形式返回结果。
3)DatabaseMeta:
有了上面的基础,就可以介绍DataBaseMeta了。DatabaseMeta代表了一个新的数据库,其通过继承模板类,用TableMeta和IdentityMetaKey来实例化模板参数来以Key-Value的形式保存数据库和表的关系。并且实现了继承自DBMeta的serialize函数来实现序列化,定义了deserialize函数实现反序列化,主要代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class DatabaseMeta : public MappedDBMeta<TableMeta, IdentityMetaKey> { static std::unique_ptr<DatabaseMeta> deserialize(unsigned int id, const std::string &serial); std::string serialize(const DBObject &parent) const; } std::unique_ptr<DatabaseMeta> DatabaseMeta::deserialize(unsigned int id, const std::string &serial) { assert(id != 0); return std::unique_ptr<DatabaseMeta>(new DatabaseMeta(id)); } std::string DatabaseMeta::serialize(const DBObject &parent) const{ const std::string &serial = "Serialize to associate database name with DatabaseMeta"; return serial; }
可以看到,对于database来说,序列化只要写固定的一个字符串下去就可以,而反序列化的时候,这个字符串也没有用到,而是直接使用DatabaseMeta对应的id来做反序列化。
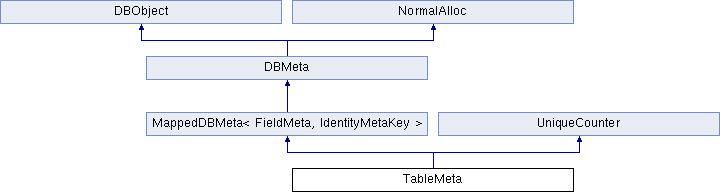
和DatabaseMeta类似,TableMeta保存了一个table的信息。上图给出了TableMeta的继承关系。Table中包含了很多的列,每个列都有自己的名字,所以其用于实例化模板的类型分别是FieldMeta和IdentityMetaKey。前者代表了表中的一个列,后者则是列名的封装。TableMeta的主要定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class TableMeta : public MappedDBMeta<FieldMeta, IdentityMetaKey>, public UniqueCounter { static std::unique_ptr<TableMeta> deserialize(unsigned int id, const std::string &serial); std::string serialize(const DBObject &parent) const; std::string getAnonTableName() const; std::vector<FieldMeta *> orderedFieldMetas() const; private: const std::string anon_table_name; uint64_t counter; //from UniqueCounter uint64_t &getCounter_() {return counter;} }
首先看其成员anno_table_name。在CryptDB中,每个明文的表名都被替换成了密文的表名。其中明文的表名被封装成了IdentityMetaKey,存储在DatabaseMeta内部的Map中作为key,加密替换以后的表名则存储在TableMeta中的成员anon_table_name中。这样,在通过明文的表名做Key,找到对应的TableMeta类型的value时,可以从其类成员anno_table_name得到加密的表名。明文和密文的对应关系就是这样存储的。
和DatabaseMeta不同的是,TableMeta还继承了UniqueCounter类,并拥有一个uint64t类型的成员counter。这个类的功能是,给counter值增加1,以及返回当前的counter值。这种增加counter的功能是为了底层的child类型能够被排序而设计的。一个表下有好几个列,这些列都是有顺序的。比如对于语句CREATE TABLE student( id integer, name value),id列和name列的元信息表示都是FieldMeta,但是id在前,name在后。这种顺序就是通过counter来记录。在使用 CREATE TABLE 语句来建表时,会建立TableMeta结构,这个过程中,由于TableMeta通过Key-Value的形式保存了表中的各个列,所以在创建过程中要在map中添加项目,也就需要创建FieldMeta结构。创建每个FieldMeta前,都获取自增的counter传递到FieldMeta中,这样一个TableMeta下的FieldMeta就可以根据这个counter值进行排序了。
最后来看看TableMeta的序列化和反序列化函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 std::unique_ptr<TableMeta> TableMeta::deserialize(unsigned int id, const std::string &serial) { assert(id != 0); const auto vec = unserialize_string(serial); //five items to be deserialized assert(5 == vec.size()); const std::string anon_table_name = vec[0]; const bool hasSensitive = string_to_bool(vec[1]); const bool has_salt = string_to_bool(vec[2]); const std::string salt_name = vec[3]; const unsigned int counter = atoi(vec[4].c_str()); return std::unique_ptr<TableMeta> (new TableMeta(id, anon_table_name, hasSensitive, has_salt, salt_name, counter)); } std::string TableMeta::serialize(const DBObject &parent) const{ const std::string &serial = serialize_string(getAnonTableName()) + serialize_string(bool_to_string(hasSensitive)) + serialize_string(bool_to_string(has_salt)) + serialize_string(salt_name) + serialize_string(std::to_string(counter)); return serial; }
可以看到,TableMeta中的序列化和反序列化会对TableMeta中的几个成员进行了处理,进行了类成员和字符串的相互转换。
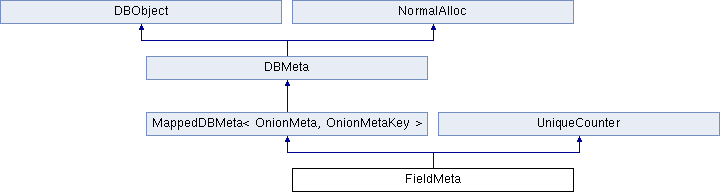
FieldMeta和TableMeta类似,也继承了UniqueCounter,因为一个Field内部包含了多个洋葱加密模型,每个洋葱代表了加密表中的一个列,这些洋葱当然也是有顺序的。FieldMeta的继承结构如下:
FieldMeta的主要定义是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class FieldMeta : public MappedDBMeta<OnionMeta, OnionMetaKey>, public UniqueCounter { public: static std::unique_ptr<FieldMeta> deserialize(unsigned int id, const std::string &serial); std::string serialize(const DBObject &parent) const; std::vector<std::pair<const OnionMetaKey *, OnionMeta *>> orderedOnionMetas() const; OnionMeta *getOnionMeta(onion o) const; private: const std::string fname; const std::string salt_name; const onionlayout onion_layout; const bool has_salt; }
对于FieldMeta,首先需要关注的是成员salt_name。对于一个Field来说,其除了被多层洋葱加密以外,还有一列随机数IV,在内部被称为salt。这个salt列有自己的名字,被保存在FieldMeta中。另一个需要关注的成员是onionlayout,是一个map结构,key是洋葱类型,value是一个vector,表示洋葱的各个层次。其示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 //洋葱类型 typedef enum onion { oDET, oOPE, oAGG, } onion; //洋葱层次 enum class SECLEVEL { OPE, DET, SEARCH, HOM, RND, }; //常见的onionlayout onionlayout NUM_ONION_LAYOUT = { {oDET, std::vector<SECLEVEL>({SECLEVEL::DETJOIN, SECLEVEL::DET, SECLEVEL::RND})}, {oOPE, std::vector<SECLEVEL>({SECLEVEL::OPE, SECLEVEL::RND})}, {oAGG, std::vector<SECLEVEL>({SECLEVEL::HOM})} }; onionlayout STR_ONION_LAYOUT = { {oDET, std::vector<SECLEVEL>({SECLEVEL::DETJOIN, SECLEVEL::DET, SECLEVEL::RND})}, {oOPE, std::vector<SECLEVEL>({SECLEVEL::OPEFOREIGN, SECLEVEL::OPE, SECLEVEL::RND})}, {oSWP, std::vector<SECLEVEL>({SECLEVEL::SEARCH})} };
可以看到,洋葱以及洋葱的层次全都通过自行定义枚举类型来实现。上面给出了针对整数类型和字符串类型的onionlayout。最后我们给出FieldMeta的序列化和反序列化函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 std::string FieldMeta::serialize(const DBObject &parent) const { const std::string &serialized_salt_name = true == this->has_salt ? serialize_string(getSaltName()) : serialize_string(""); std::string sql_type_string = std::to_string((int)sql_type); const std::string serial = serialize_string(fname) + serialize_string(bool_to_string(has_salt)) + serialized_salt_name + serialize_string(TypeText<onionlayout>::toText(onion_layout)) + serialize_string(TypeText<SECURITY_RATING>::toText(sec_rating)) + serialize_string(std::to_string(uniq_count)) + serialize_string(std::to_string(counter)) + serialize_string(bool_to_string(has_default)) + serialize_string(default_value) + serialize_string(sql_type_string);//added by shaoyiwen return serial; } std::unique_ptr<FieldMeta> FieldMeta::deserialize(unsigned int id, const std::string &serial) { assert(id != 0); const auto vec = unserialize_string(serial); assert(10 == vec.size());//We add one item,so there are ten items now const std::string fname = vec[0]; const bool has_salt = string_to_bool(vec[1]); const std::string salt_name = vec[2]; const onionlayout onion_layout = TypeText<onionlayout>::toType(vec[3]); const SECURITY_RATING sec_rating = TypeText<SECURITY_RATING>::toType(vec[4]); const unsigned int uniq_count = atoi(vec[5].c_str()); const unsigned int counter = atoi(vec[6].c_str()); const bool has_default = string_to_bool(vec[7]); const std::string default_value = vec[8]; enum enum_field_types sql_type = ((enum enum_field_types)atoi(vec[9].c_str()));//new field added return std::unique_ptr<FieldMeta> (new FieldMeta(id, fname, has_salt, salt_name, onion_layout, sec_rating, uniq_count, counter, has_default, default_value,sql_type)); }
可以看到,序列化和反序列化的函数和TableMeta是类似的,就是一些相关的成员转化成字符串,以及从字符串转换回各个成员的过程。
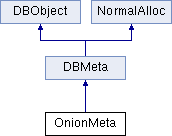
和前面的TableMeta,FieldMeta以及DatabaseMeta不同,OnionMeta没有继承MappedDBMeta类型,而是直接继承了DBMeta。其继承结构如下:
由于没有继承MappedDBMeta,所以其不会通过Key-Value的形式来保存children。对于OnionMeta来说,其下一层的类型是Enclayer,这种加密层的数据是直接通过std::vector来保存的。其主要的实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class OnionMeta : public DBMeta { static std::unique_ptr<OnionMeta> deserialize(unsigned int id, const std::string &serial); //from DBMeta std::string serialize(const DBObject &parent) const; //from DBMeta std::vector<DBMeta *> fetchChildren(const std::unique_ptr<Connect> &e_conn); bool applyToChildren(std::function<bool(const DBMeta &)>) const; UIntMetaKey const &getKey(const DBMeta &child) const; std::string getAnonOnionName() const; SECLEVEL getSecLevel() const; private: std::vector<std::unique_ptr<EncLayer> > layers; const std::string onionname; const unsigned long uniq_count; };
OnionMeta代表了一个洋葱。在CryptDB中,一个洋葱有很多的层次,每个层次代表一次加密,原始列的数据被这个洋葱中的多个层次依次进行加密。加密以后的列有列名,通过这里的onionname成员来记录。uniq_count成员则是用于onionmeta的排序,之前已经做过介绍。layers成员是通过vector类型来对加密层次进行记录。序列化和反序列化的函数和前面的类似,这里不再给出。
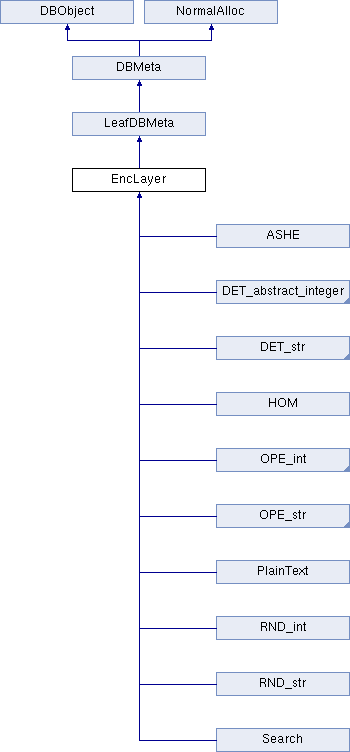
EncLayers 最后就是加密层了。加密层是整个元数据相关类的最底层,其继承结构如下:
首先来看LeafDBmeta类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class LeafDBMeta : public DBMeta { public: //from DBMeta std::vector<DBMeta *> fetchChildren(const std::unique_ptr<Connect> &e_conn) { return std::vector<DBMeta *>(); } //from DBMeta bool applyToChildren(std::function<bool(const DBMeta &)> fn) const { return true; } //from DBMeta AbstractMetaKey const &getKey(const DBMeta &child) const { assert(false); } };
可以看到,LeafDBMeta的作用是继承DBMeta,并实现其中三个函数。fetchChildren返回空的vector,applyToChildren也是什么也不做。这是因为对于EncLayers来说,已经没有更下一层的类,没有children的概念,当然就应该这么做实现。所以这里通过LeafDBMeta把这些性质都放到一起,作为EncLayer以及其下层类的共同特征。
然后来看EncLayers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class EncLayer : public LeafDBMeta { public: virtual SECLEVEL level() const = 0; virtual std::string name() const = 0; // returns a rewritten create field to include in rewritten query virtual Create_field * newCreateField(const Create_field &cf, const std::string &anonname = "") const = 0; virtual Item *decryptUDF(Item * const col, Item * const ivcol = NULL) const { thrower() << "decryptUDF not supported"; } virtual Item *encrypt(const Item &ptext, uint64_t IV) const = 0; virtual Item *decrypt(const Item &ctext, uint64_t IV) const = 0; // virtual std::string doSerialize() const = 0; std::string serialize(const DBObject &parent) const { return serial_pack(this->level(), this->name(), this->doSerialize()); } };
EncLayer代表了一个加密层次的抽象,所以其首先应该有加密和解密函数,用于对数据做加解密。在这个层次,数据的加解密的对象是Item,这是一个MySQL的parser中定义的类型,代表了解析以后的SQL语句的语法树中的一个节点。加解密函数都有另一个参数IV,是用于构造随机性的随机数。对于具体的一种加密算法,其继承EncLayer以后,只要实现相关的函数就可以。
每个加密层有自己的名字,有自己层次对应的枚举值,对于具体的加密类,还有自己本身特定的数据结构。这三类信息都需要在序列化的时候被保存,这就是EncLayers的serialize 函数的实现。对于反序列化函数,则依然在底层的类(DET_str,OPE_int等)中通过static函数的形式给出。
newCreateField 函数是为了处理数据类型的变化:数据经过加密算法的处理,其数据类型和数据长度会发生变化,加密层的newCreateField要能够返回加密以后的数据类型。这种类型的信息封装在Create_field类里面了,这也是MySQL的parser中定义的类,具体细节不在此展开。
decryptUDF 函数用于洋葱层次的调整。举例来说,当一个查询需要使用where xx=xx 的条件时,需要使用洋葱层次DET,而如果此时洋葱的实际层次是RND,则需要在MySQL端执行解密函数,剥掉RND层。这个操作通过UDF来完成,而decryptUDF就是用来生成这个UDF语句的。
以RND_str为例 对于具体的加密算法层,只要继承EncLayer并实现上面介绍的几个函数就可以了,这里以RND_str作为例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 class RND_str : public EncLayer { public: RND_str(const Create_field &cf, const std::string &seed_key); // serialize and deserialize std::string doSerialize() const {return rawkey;} RND_str(unsigned int id, const std::string &serial); SECLEVEL level() const {return SECLEVEL::RND;} std::string name() const {return "RND_str";} Create_field * newCreateField(const Create_field &cf, const std::string &anonname = "") const; Item * encrypt(const Item &ptext, uint64_t IV) const; Item * decrypt(const Item &ctext, uint64_t IV) const; Item * decryptUDF(Item * const col, Item * const ivcol) const; private: const std::string rawkey; static const int key_bytes = 16; static const bool do_pad = true; const std::unique_ptr<const AES_KEY> enckey; const std::unique_ptr<const AES_KEY> deckey; }; Create_field * RND_str::newCreateField(const Create_field &cf, const std::string &anonname) const { const auto typelen = AESTypeAndLength(cf, do_pad); return arrayCreateFieldHelper(cf, typelen.second, typelen.first, anonname, &my_charset_bin); } Item * RND_str::encrypt(const Item &ptext, uint64_t IV) const { const std::string &enc = encrypt_AES_CBC(ItemToString(ptext), enckey.get(), BytesFromInt(IV, SALT_LEN_BYTES), do_pad); return new (current_thd->mem_root) Item_string(make_thd_string(enc), enc.length(), &my_charset_bin); } Item * RND_str::decrypt(const Item &ctext, uint64_t IV) const { const std::string &dec = decrypt_AES_CBC(ItemToString(ctext), deckey.get(), BytesFromInt(IV, SALT_LEN_BYTES), do_pad); return new (current_thd->mem_root) Item_string(make_thd_string(dec), dec.length(), &my_charset_bin); } static udf_func u_decRNDString = { LEXSTRING("cryptdb_decrypt_text_sem"), STRING_RESULT, UDFTYPE_FUNCTION, NULL, NULL, NULL, NULL, NULL, NULL, NULL, 0L, }; Item * RND_str::decryptUDF(Item * const col, Item * const ivcol) const { List<Item> l; l.push_back(col); l.push_back(get_key_item(rawkey)); l.push_back(ivcol); return new (current_thd->mem_root) Item_func_udf_str(&u_decRNDString, l); }
上面的例子给出了一个实际的RND_str加密层的实现。其他层的实现是类似的:本文基于修改版的CryptDB,采用类似的方法添加了新的加密层ASHE 。
上面的代码也是对MySQL parser中的类型进行操作,这里先忽略这个细节,直接关注每个函数的功能:
初始化的时候,对AES算法进行初始化
encrypt与decrypt函数使用AES算法对Item类型进行加解密,加解密都要求先把Item类型转化成普通的string类型,然后对string进行加解密处理,处理完成以后又重新转化成Item类型
decryptUDF在这里返回了一个UDF,名字是cryptdb_decrypt_text_sem,通过调用这个UDF来实现RND层次的洋葱解密
newCreateField函数对string长度做了padding的处理,要求string长度是AES的blcok大小的整数倍。举例来说一个**CREATE TABLE student(name varchar(20))**,在block大小是16的情况下,20会被这个函数被扩展成32。这种数据类型和长度的信息都记录在了Create_field类结构中
元数据存储格式 最后介绍元数据在数据库中的存储格式。首先看本地的数据库中用于记录元数据的表的定义:
1 2 3 4 5 6 7 8 9 CREATE TABLE `MetaData` ( `serial_object` varbinary(500) NOT NULL, `serial_key` varbinary(500) NOT NULL, `parent_id` bigint(20) NOT NULL, `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`), UNIQUE KEY `id` (`id`) )
在上面的层次结构中,一部分对象通过Key-Value的形式被记录,还有最后一层的EncLayers,虽然是以数组的形式存储,但是每一层也有自己的枚举的名字,也可以看成Key-Value。这样,就可以用seria_key和serial_object两个列来记录这个Key-Value。每个元数据管理对象有自己继承自DBObject的id,这个id存储在表中的id这列。parent_id表示的是当前的类上层的类的id。下面给出一个例子:
假设我们执行了以下两个语句:
1 2 CREATE DATABASE db; CREATE TABLE student(id integer);
并且我们对于整数列id只使用一个DET洋葱进行加密。那么,初始化有三个洋葱层:DETJOIN DET RND。那么语句执行完以后的数据库中表内容如下:
serial_object
serial_key
parent_id
id
Serialize to associate database name with DatabaseMeta
2_db
0
1
16_table_IAUMLMEJLL4_TRUE4_ TRUE20_tableSalt_JXOLNITEJN1 _1
7_student
1
2
2_id4_TRUE18_cdb_saltYHRATVO WOU18_CURRENT_NUM_LAYOU T9_SENSITIVE1_01_35_FALSE0_ 1_3
2_id
2
3
13_CATSNIAGMMoEq1_07_ DETJOIN
3_oEq
3
4
67 DETJOIN DETJOIN_int 16_???19_ MYSQL_TYPE_LONGLONG1_0 20_18446744073709551615
1_0
4
5
67 DET DET_int 16_???19_MYSQL_TYP E_LONGLONG1_020_184467 44073709551615
1_1
4
6
67 RND RND_int 16_???19_MYSQL_TYP E_LONGLONG1_020_1844674 4073709551615
1_2
4
7
从表中可以看出,建立db数据库的时候,写入了第一行记录。id是1,parent_id是0。建立student表的时候,db有了第一个child,于是插入一条新记录:id是2,parent_id是1。对于表来说,有一个field是id,所以有第三条记录,parent_id是2,表示这是studnet表的field。对于field id来说,包含了一个洋葱DET,这个洋葱有三个层次。所以有后面几行数据。而serial_boject以及serial_key则是之前介绍的序列化函数处理的结果(对于不可显示字符采用???替换)。通过这个例子,我们可以发现,通过serial_object和serial_key可以保存元数据管理类,这些字符串是通过serialize函数来编码生成的。通过id和parent_id,可以保存这些类之间的层次关系。
小结 本文介绍了CryptDB中元数据管理相关的类的设计。由于需要保存database,table,field,onion,layer这样的层次关系,分别设计了DatabaseMeta,TableMeta,FieldMeta,OnionMeta,Enclayer类。Enclayer之上,上下层的关系通过继承MappedDBMeta,使用map结构进行保存,EncLayer则直接通过vector保存在OnionMeta中。每个类都有自己的序列化和反序列函数,需要把类自身以及类之间的关系编码写入到MySQL,本文通过一个例子来说明了这种编码方式。
参考文献 https://github.com/yiwenshao/Practical-Cryptdb