CryptDB要进行数据加密,需要实现具体的加密算法,然后使用加密层类型来进行封装。如果用户想在其上实现新的功能,一方面需要实现加密算法,一方面要添加加密层以及其他相关辅助结构。本文介绍这两者之间的一些接口设计,方便大家基于现有代码做实验。
加密算法
CryptDB使用了AES,OPE,blowfish,Pailliar,Search算法,用到了openssl以及NTL库,相关代码全部位于crypto目录下。这里主要关注其对外的接口,忽略算法的实现步骤。要实现新的算法,需要使用类似的方法定义接口并做内部实现。
几种算法接口介绍
blowfish
blowfish算法实现位于crypto/blowfish.hh中。相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class blowfish {
public:
blowfish(const std::string &key) {
BF_set_key(&k, key.size(), (const uint8_t*) key.data());
}
uint64_t encrypt(uint64_t pt) const {
uint64_t ct;
block_encrypt(&pt, &ct);
return ct;
}
uint64_t decrypt(uint64_t ct) const {
uint64_t pt;
block_decrypt(&ct, &pt);
return pt;
}
static const size_t blocksize = 8;
private:
BF_KEY k;
};
|
可以看到,要使用blowfish,首先要有密钥key来完成初始化类,然后分别使用encrypt和decrypt函数来实现加解密。算法处理的数据类型是uint64_t。
AES
CryptDB使用了两种AES的模式,其加解密相关的函数如下:
1
2
3
4
5
6
7
8
9
| string
encrypt_AES_CBC(const string &ptext, const AES_KEY * enckey, string salt, bool dopad);
string
decrypt_AES_CBC(const string &ctext, const AES_KEY * deckey, string salt, bool dounpad);
string
encrypt_AES_CMC(const string &ptext, const AES_KEY * enckey, bool dopad);
string
decrypt_AES_CMC(const string &ctext, const AES_KEY * deckey, bool dopad);
|
可以看到,使用AES也是需要有密钥,通过encrypt和decrypt函数来完成加解密功能。处理的数据类型是string。
Pailliar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class Paillier_priv : public Paillier{
NTL::ZZ decrypt(const NTL::ZZ &ciphertext) const;
NTL::ZZ encrypt(const NTL::ZZ &plaintext);
NTL::ZZ add(const NTL::ZZ &c0, const NTL::ZZ &c1) const;
...
}
//使用举例
Paillier_priv * sk;
sk = new Paillier_priv();
ZZ pt0 = NTL::to_ZZ(1);
ZZ pt1 = NTL::to_ZZ(2);
const ZZ enc0 = sk->encrypt(pt0);
const ZZ dec0 = sk->decrypt(enc0);
const ZZ enc1 = sk->encrypt(pt1);
const ZZ dec1 = sk->decrypt(enc1);
assert((pt0+pt1)==sk->decrypt(sk->add(enc0,enc1)));
|
上面给出了一个Pailliar使用的例子,可以看到,Pailliar算法提供了加解密以及密文相加得到密文的功能(同态加法)。处理过程使用了NTL库中的ZZ大整数类型。
Search
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class search_priv : public search {
public:
search_priv(const std::string &key, size_t csize_arg = defsize)
: search(csize_arg), master_key(key) {}
std::vector<std::string>
transform(const std::vector<std::string> &words);
std::string
wordkey(const std::string &word);
private:
std::string
transform(const std::string &word);
std::string master_key;
};
|
对于search,首先需要对输入文字做划分,形成不同的关键字,对关键字进行加密,这是函数transform的作用。在进行match的时候,则是通过wordKey函数对关键字处理形成token,然后使用token调用match函数进行匹配,输出的结果是一个bool类型。
OPE
OPE算法对于字符串和整数,实现分别如下:
1
2
3
4
5
| class OPE {
NTL::ZZ encrypt(const NTL::ZZ &ptext);
NTL::ZZ decrypt(const NTL::ZZ &ctext);
};
|
1
2
3
4
5
6
7
8
9
10
11
12
|
OPE ope(rawkey,8*plain_size,8*ciph_size);
std::string ptext="helloworld";
std::string ps = toUpperCase(ptext);
if (ps.size() < plain_size)
ps = ps + std::string(plain_size - ps.size(), 0);
uint32_t pv = 0;
for (uint i = 0; i < plain_size; i++) {
pv = pv * 256 + static_cast<int>(ps[i]);
}
const ZZ enc = ope.encrypt(to_ZZ(pv));
|
可以看到,对于整数来说,提供了加解密函数。并且由于OPE的性质,密文有保序的性质。对于字符串,还是同样的类实现,只是加密的时候做了处理,使得字符串加密依然可以保序。
接口总结
可以看到,在crypto目录中的代码提供了底层的加密功能,大部分类都提供了加解密函数encrypt和decrypt,如果算法有特定功能如同态加,则需要添加额外的函数。这些底层库没有使用MySQL内部数据类型。 所以,如果要自己添加新的算法,首先需要在crypto目录添加底层加密代码,对外提供encrypt,decrypt以及密文计算函数。 这部分代码可以独立编译运行以及测试。
加密层
首先,下面代码中用到的加密层以及洋葱都是枚举类型,其相关的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| //位于util/onions.hh
typedef enum onion {
oDET,
oOPE,
oAGG,
oSWP,
oPLAIN,
oBESTEFFORT,
oASHE,
oINVALID,
} onion;
enum class SECLEVEL {
INVALID,
PLAINVAL,
OPEFOREIGN,
OPE,
DETJOIN,
DET,
SEARCH,
HOM,
ASHE,
RND,
};
|
有了这些枚举类型表示洋葱和加密层,接下来就需要具体的加密层的实现,以及一些辅助类来完成加密层的管理。
加密层实现
加密层相关的类主要实现了以下几个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class EncLayer : public LeafDBMeta {
virtual Create_field *
newCreateField(const Create_field &cf,
const std::string &anonname = "") const = 0;
virtual Item *encrypt(const Item &ptext, uint64_t IV) const = 0;
virtual Item *decrypt(const Item &ctext, uint64_t IV) const = 0;
virtual Item *decryptUDF(Item * const col, Item * const ivcol = NULL)
const;
virtual std::string doSerialize() const = 0;
std::string serialize(const DBObject &parent) const
{
return serial_pack(this->level(), this->name(),
this->doSerialize());
}
};
|
其类的继承结构之前已经介绍过,如下图:
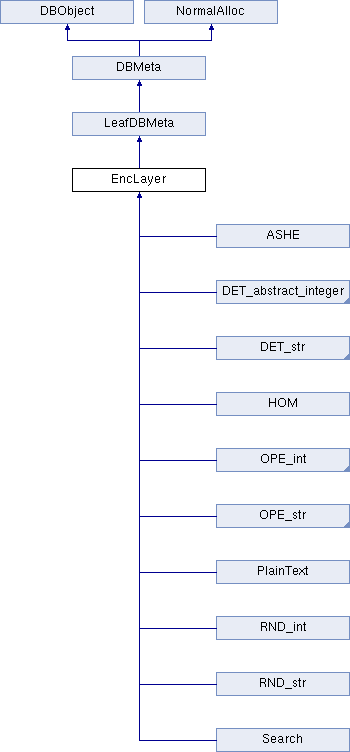
相关要点如下:
- serialize函数实现了加密层的序列化
- 反序列化功能在LayerFactory管理类中实现,后面会介绍
- 加解密函数encrypt和decrypt,是对上面介绍的crypto目录中的底层库的封装。由于这里处理的都是item类型,所以需要进行item类型和普通数据类型的互相转换
- decryptUDF用于返回一个UDF函数,做洋葱层次调整
- newCreateField用来处理加密带来的数据类型的变化。比如原来是整数类型,经过了Pailliar的加密,就变成了二进制字符串类型
除了上面的通用函数,具体的加密层也会有自己特有的函数来实现密文计算功能。
加密层的实现举例
我们以pailliar(HOM)为例,给出一个加密层实现的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class HOM : public EncLayer {
public:
Create_field * newCreateField(const Create_field &cf,
const std::string &anonname = "")
const;
Item *encrypt(const Item &p, uint64_t IV) const;
Item * decrypt(const Item &c, uint64_t IV) const;
//expr is the expression (e.g. a field) over which to sum
Item *sumUDA(Item *const expr) const;
Item *sumUDF(Item *const i1, Item *const i2) const;
protected:
std::string const seed_key;
static const uint nbits = 1024;
mutable Paillier_priv * sk;
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Create_field *
HOM::newCreateField(const Create_field &cf,
const std::string &anonname) const{
return arrayCreateFieldHelper(cf, 2*nbits/BITS_PER_BYTE,
MYSQL_TYPE_VARCHAR, anonname,
&my_charset_bin);
}
Item *
HOM::encrypt(const Item &ptext, uint64_t IV) const{
const ZZ enc = sk->encrypt(ItemIntToZZ(ptext));
return ZZToItemStr(enc);
}
Item *
HOM::decrypt(const Item &ctext, uint64_t IV) const {
const ZZ enc = ItemStrToZZ(ctext);
const ZZ dec = sk->decrypt(enc);
return ZZToItemInt(dec);
}
|
上面的简化代码展示了以下三点
- 加密层类型是对crypto目录中的加密相关类的封装,比如这里的HOM封装了Paillier_priv类型
- encrypt与decrypt中,对item类型进行转换,使得其能够适配crypto目录中相关底层库进行加解密,之后又将结果转换为item类型返回
- sumUDF和sumUDA返回UDF,来实现MySQL Server端的同态加法操作(参考之前的文章以及原始论文中的介绍),其相关UDF的实现位于udf/edb.cc中,关于UDF可以参考这里,如果要自己写加密层,同样需要熟悉UDF的编写规则
- newCreateField函数返回了新的Create_field类型,来表示经过HOM加密以后的数据类型
对于最后一点,我们继续看arrayCreateFieldHelper函数内部的具体实现,其简化的示例代码如下:
1
2
3
4
5
6
| Create_field*
lowLevelcreateFieldHelper(const Create_field *f0){
f0->length = field_length;
f0->sql_type = type;
return f0;
}
|
可以看到,Create_field中有lenghth和sql_type两个成员。一开始的时候,sql_type是MYSQL_TYPE_LONG,是表示整数类型。而这里的函数只要把sql_type变为MYSQL_TYPE_VARCHAR并设置对应的长度为256就行了。
再举一个实际的例子,我们执行这样的SQL语句:CREATE TABLE student(id integer),并且对id这列只设置HOM一个洋葱,在MySQL端执行SHOW CREATE TABLE以后看到的结果是:
1
2
3
4
| //这里省略了额外的salt列
CREATE TABLE `table_NRDDWIRZPY` (
`NSPUQRQGCEoADD` varbinary(256) DEFAULT NULL
);
|
可以看到,原来的integer变成了varbinary(256),这个变化就是通过newCreateField函数的Create_field机制实现的。我们在处理阶段修改了解析以后的LEX结构中的Create_field成员,所以在将LEX结构转化回字符串类型的SQL语句时,就可以得到包含正确数据类型的SQL语句。
加密层管理
加密层的创建依靠LayerFactory结构,不同的加密层有自己的factory。而这些factory又通过EncLayerFactory类来实现管理,其创建相关的代码以及类的结构如下:

1
2
3
4
5
6
7
8
9
10
11
|
class EncLayerFactory {
public:
static std::unique_ptr<EncLayer>
encLayer(onion o, SECLEVEL sl, const Create_field &cf,
const std::string &key);
// creates EncLayer from its serialization
static std::unique_ptr<EncLayer>
deserializeLayer(unsigned int id, const std::string &serial);
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| std::unique_ptr<EncLayer>
EncLayerFactory::encLayer(onion o, SECLEVEL sl, const Create_field &cf,
const std::string &key)
{
switch (sl) {
case SECLEVEL::RND: {return RNDFactory::create(cf, key);}
case SECLEVEL::DET: {return DETFactory::create(cf, key);}
case SECLEVEL::DETJOIN: {return DETJOINFactory::create(cf, key);}
case SECLEVEL::OPE:{return OPEFactory::create(cf, key);}
case SECLEVEL::OPEFOREIGN:{return OPEFOREIGNFactory::create(cf,key);}
case SECLEVEL::HOM: {return HOMFactory::create(cf, key);}
case SECLEVEL::ASHE: {return std::unique_ptr<EncLayer>(new ASHE(cf,key));}
case SECLEVEL::SEARCH: {
return std::unique_ptr<EncLayer>(new Search(cf, key));
}
case SECLEVEL::PLAINVAL: {
return std::unique_ptr<EncLayer>(new PlainText());
}
default:{}
}
FAIL_TextMessageError("unknown or unimplemented security level");
}
std::unique_ptr<EncLayer>
EncLayerFactory::deserializeLayer(unsigned int id,
const std::string &serial){
assert(id);
const SerialLayer li = serial_unpack(serial);
switch (li.l) {
case SECLEVEL::RND:
return RNDFactory::deserialize(id, li);
case SECLEVEL::DET:
return DETFactory::deserialize(id, li);
case SECLEVEL::DETJOIN:
return DETJOINFactory::deserialize(id, li);
case SECLEVEL::OPEFOREIGN:
return OPEFOREIGNFactory::deserialize(id,li);
case SECLEVEL::OPE:
return OPEFactory::deserialize(id, li);
case SECLEVEL::HOM:
return std::unique_ptr<EncLayer>(new HOM(id, serial));
case SECLEVEL::ASHE: return std::unique_ptr<EncLayer>(new ASHE(id, serial));
case SECLEVEL::SEARCH:
return std::unique_ptr<EncLayer>(new Search(id, serial));
case SECLEVEL::PLAINVAL:
return std::unique_ptr<EncLayer>(new PlainText(id));
default:{}
}
FAIL_TextMessageError("unknown or unimplemented security level");
}
|
从上面可以看到LayerFactory系列的类,主要提供了create和deserialize函数,前者用于在内存中直接创建加密层,后者用于对磁盘读取的数据做反序列化来创建加密层,上一篇文章介绍的元数据读取过程中的反序列化函数,就来自这里的LayerFactory。
总结
通过本文我们可以发现,crypto目录实现了底层加密库,主要就是要对外提供encrypt,decrypt,以及密文计算函数。这个库操作的数据类型是普通的字符串和整数。这个模块和MySQL没有依赖,可以独立编译。
CryptDB需要对MySQL的parser中的LEX结构中的Item类型做加密,底层加密库不能直接处理Item,所以在EncLayer中要做一个封装,这部分的内容主要实现在main/CryptoHandlers.cc,用于处理数据类型的转化。此外,EncLayer还需要处理序列化,UDF返回等功能。为了辅助加密层类型的使用,设计了LayerFactory系列的类,用于构造加密层类,这个构造分为普通构造和反序列化构造。这些factory类又通过EncLayerFactory类型来进行统一管理。通过这些机制,底层的加密库就和CryptDB的实现连接起来了,CryptDB会调用封装好的EncLayer,而不直接使用底层的加密库。
参考文献
https://github.com/yiwenshao/Practical-Cryptdb